MySql相似度搜索
前言
之前一直在用模糊查询来模拟搜索引擎的搜索功能,但这种查询方式得到的结果并不太理想。比如,有一条信息台湾长荣海运巨型货柜轮“长赐号”23日搁浅在苏伊士运河,造成双向航道阻塞。外媒最新报道称,“长赐号”搁浅前,其航行速度严重超出运河的限制标准。埃及总统目前已下令减轻搁浅货轮的负荷。,如果使用关键字苏伊士运河搁浅货轮来搜索该信息,则匹配不了对应项。这就是一般模糊查询的缺陷之处,搜索的关键字必须要一一对应上信息才会有结果,因此要让搜索功能有类似搜索引擎的效果就要使用相似度/分词查询。
mysql中的全文索引
从mysql5.7.6开始,mysql内置了ngram全文解析器,用于支持中文、日文、韩文的分词。通过自带引擎的分词,我们可以通过对字段建立FULLTEXT索引,进行搜索时分词器会将关键字分词进行模糊查询最后整合出结果集。
使用全文索引的注意事项
- 只有varchar、char、text的字段才能创建FULLTEXT索引
- 中文分词的长度用ngram_token_size设定
- 当对表写入大量数据时,先建表写入数组再建索引速度会更快
使用方法
- 先设置分词长度
ngram_token_size,大部分中文词语都是两个字符起步,因此在控制台中输入以下语句或在mysql配置文件mysqld --ngram_token_size=2
my.ini中设置ngram_token_size=2,设置结果可通过下面语句检验SHOW VARIABLES LIKE 'ngram_token_size'
- 对表中要进行分词查询的字段设置全文索引
# all_table是表名,full_index是索引名,comic_name是字段名
# 这里必须指定分词器
ALTER TABLE all_comic ADD FULLTEXT INDEX `full_index`(`comic_name`) WITH PARSER ngram - 使用MATCH()…AGAINST()语句进行查询
SELECT * FROM all_comic
WHERE MATCH (comic_name)
against('異世界後宮')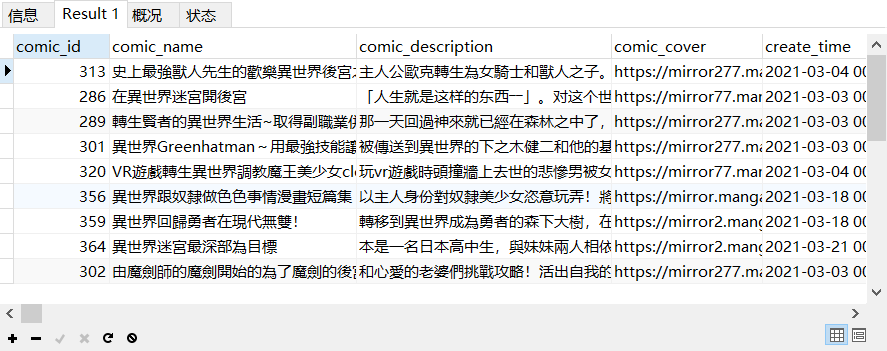
全文检索的模式
自然语言模式(NATURAL LANGUAGE MODE)。自然语言模式是MySQL 默认的全文检索模式。自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
BOOLEAN模式(BOOLEAN MODE)。BOOLEAN模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
使用例子
SELECT * FROM all_comic |
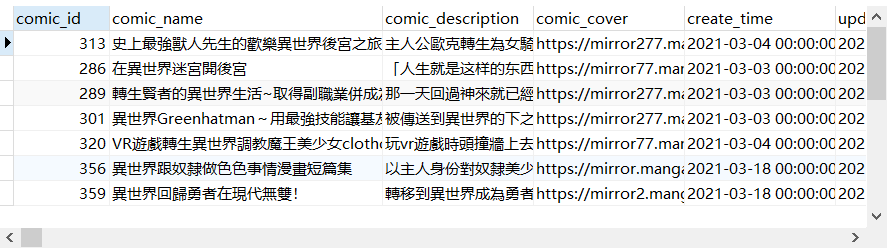
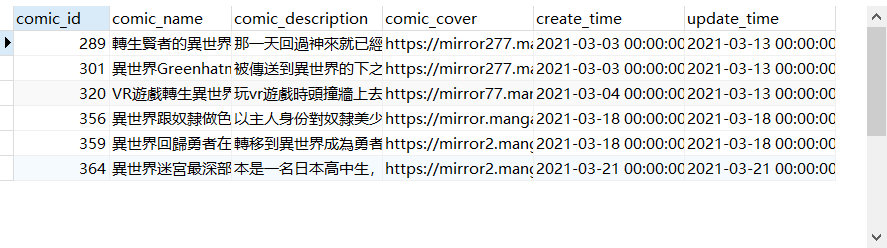
- BOOLEAN模式其他使用方式
来源于https://www.jianshu.com/p/c48106149b6a/
'apple banana' |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 KBdog's blog!
打赏
 微信
微信 支付宝
支付宝

评论
ValineDisqus

